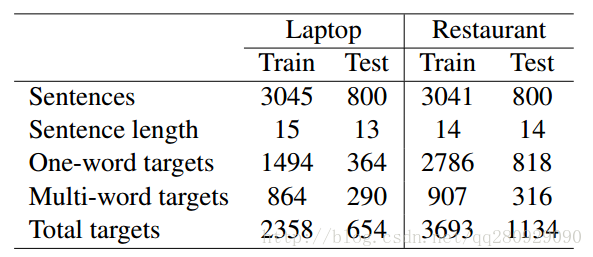
SemEval-2014 Task 4数据集主要用于细粒度情感分析,包含Laptop和Restaurant两个领域,每个领域的数据集都分为训练数据、验证数据(从训练数据分离出来)和检测数据,非常适用于有监督的机器学习算法或者深度学习算法,如LSTM等。文件格式为.xml,其数据统计如下:
下载地址为: SemEval-2014 Task 4数据集
该语料库为餐馆评论数据,收集自Citysearch New York网站,可用于细粒度的情感分析任务中,即aspect extraction任务当中。在本资源中,分为原始数据和处理后数据两个别,其统计如下:
其中,训练数据不包括标注信息;测试数据中包括标注信息,标注类别为预先定义的6个aspect类型,依次为Food、Staff、Ambience、Price、Anecdotes和Miscellaneous,可用于验证模型的有效性;在处理后数据文件夹中,还包括对应的词嵌入模型。
下载地址:Citysearch corpus
该语料为啤酒评论数据,共150W条评论,可用于细粒度的情感分析任务当中,即aspect extraction任务当中。
由于资源大小的限制,本资源分为原始数据和处理后的数据。在原始数据当中,包含1000条带标注信息的评论,共9245条句子,标注类别为Feel、Look、Smell、Taste和Overall五种Aspect类别;在处理后数据当中,包含相应的词嵌入模型。
原始数据下载地址:BeerAdvocate–Source
处理后数据下载地址:BeerAdvocate–Preprocess
该语义共包括日文跟英语两种语言,主要是商品评论,评论篇幅都非常短,可以被应用于篇章级或者短语级的情感分析任务。数据集被分为训练数据、测试数据、带标签的检测数据三个文件,共有正向和负向两种极性。
下载地址:NLPCC2014评估任务2_基于深度学习的情感分类
该语义主要用于识别微博观点句中的评判对象跟极性。训练数据由两个微博主题构成,每个主题各一百条,内含标注及数据表明。
下载地址:NLPCC2013评估任务_中文微博观点要素抽取
该语料主要用于识别出整条微博所抒发的心情,不是简单的褒贬分类「情感博客」,而是涉及到多个细粒度情绪类型(例如悲伤、忧愁、快乐、兴奋等),属于细粒度的情感分类问题。
下载地址:NLPCC2013评估任务_中文微博情绪识别
给定已标明倾向性的中文评论数据和英语情感词典,要求只运用给出的英语情感资源进行英文评论的情感偏好分类。该任务侧重考察多语言环境下情感资源的迁移能力,有助于解决不同语言中情感资源分布的不均衡问题。
下载地址:NLPCC2013评估任务_跨领域情感分类
该语料主要用于英文微博中的情感句识别、情感倾向性分析跟情感要素抽取。
下载地址:NLPCC2012评估任务_面向中文微博的情感分析
该语料由电影评论构成,其中持肯定跟否定态度的各1,000 篇;另外也有标注了褒贬极性的语句各5331句,标注了主客观标签的语句各5000句。该语义可以被应用于各种粒度的情感分析,如成语、句子和篇章级情感分析研究中。
下载地址:康奈尔大学影评数据集
Janyce Wiebe等人所开发的MPQA(Multiple-Perspective QA)库:包含535 篇不同视角的新闻评论,它是一个进行了深度标注的语料库。其中标注者为每个语句手工标注出一些情感信息,如观点持有者、评价对象、主观表达式并且其极性与密度。
下载地址:MPQA
该语料主要来自于Twitter上面的评论数据集,分为训练数据和检测数据,分别有6248条和692条Twitter。在文件中,每条推特被分为三行,第一行为评论句子、第二行为评价对象、第三行为情感极性。通常每条语句只包括一个评价对象。在感情极性中,用-1、0、1分别代表负向、中性、正向,三个极性的条数分别在语料中占25%、50%、25%。该语料来自于以下工作。
广州及时雨私家侦探(广州本地私家侦探公司)
微信:185-2064-4544
电话:185-2064-4544
地址:广州市天河区